3.3. Stochastic Gradient Descent¶
Stochastic Gradient Descent (SGD) is a simple yet very efficient approach to discriminative learning of linear classifiers under convex loss functions such as (linear) Support Vector Machines and Logistic Regression. Even though SGD has been around in the machine learning community for a long time, it has received a considerable amount of attention just recently in the context of large-scale learning.
SGD has been successfully applied to large-scale and sparse machine learning problems often encountered in text classification and natural language processing. Given that the data is sparse, the classifiers in this module easily scale to problems with more than 10^5 training examples and more than 10^4 features.
The advantages of Stochastic Gradient Descent are:
- Efficiency.
- Ease of implementation (lots of opportunities for code tuning).
The disadvantages of Stochastic Gradient Descent include:
- SGD requires a number of hyperparameters including the regularization parameter and the number of iterations.
- SGD is sensitive to feature scaling.
3.3.1. Classification¶
Warning
Make sure you permute (shuffle) your training data before fitting the model or use shuffle=True to shuffle after each iterations.
The class SGDClassifier implements a plain stochastic gradient descent learning routine which supports different loss functions and penalties for classification.
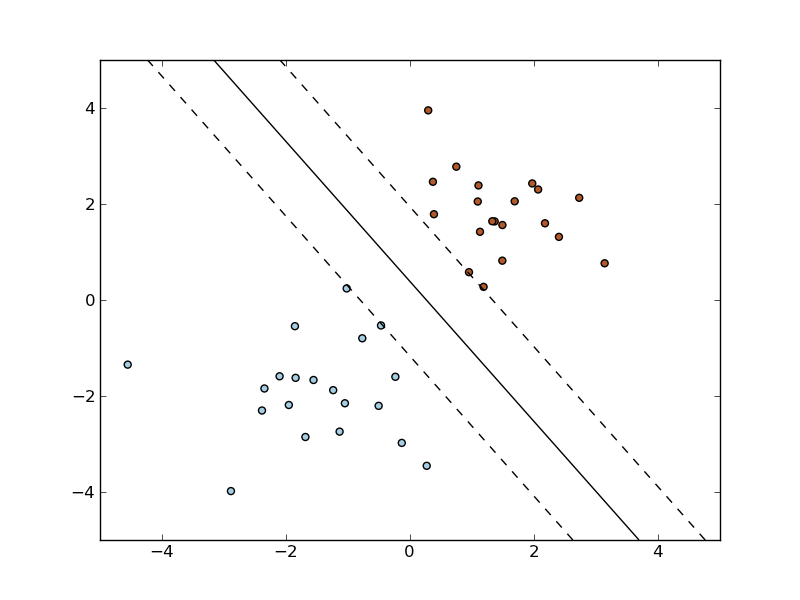
As other classifiers, SGD has to be fitted with two arrays: an array X of size [n_samples, n_features] holding the training samples, and an array Y of size [n_samples] holding the target values (class labels) for the training samples:
>>> from scikits.learn.linear_model import SGDClassifier
>>> X = [[0., 0.], [1., 1.]]
>>> y = [0, 1]
>>> clf = SGDClassifier(loss="hinge", penalty="l2")
>>> clf.fit(X, y)
SGDClassifier(loss='hinge', n_jobs=1, shuffle=False, verbose=0, n_iter=5,
fit_intercept=True, penalty='l2', rho=1.0, alpha=0.0001)
After being fitted, the model can then be used to predict new values:
>>> clf.predict([[2., 2.]])
array([ 1.])
SGD fits a linear model to the training data. The member coef_ holds the model parameters:
>>> clf.coef_
array([ 9.90090187, 9.90090187])
Member intercept_ holds the intercept (aka offset or bias):
>>> clf.intercept_
array(-9.9900299301496904)
Whether or not the model should use an intercept, i.e. a biased hyperplane, is controlled by the parameter fit_intercept.
To get the signed distance to the hyperplane use decision_function:
>>> clf.decision_function([[2., 2.]])
array([ 29.61357756])
The concrete loss function can be set via the loss parameter. SGDClassifier supports the following loss functions:
- loss=”hinge”: (soft-margin) linear Support Vector Machine.
- loss=”modified_huber”: smoothed hinge loss.
- loss=”log”: Logistic Regression
The first two loss functions are lazy, they only update the model parameters if an example violates the margin constraint, which makes training very efficient. Log loss, on the other hand, provides probability estimates.
In the case of binary classification and loss=”log” you get a probability estimate P(y=C|x) using predict_proba, where C is the largest class label:
>>> clf = SGDClassifier(loss="log").fit(X, y)
>>> clf.predict_proba([[1., 1.]])
array([ 0.99999949])
The concrete penalty can be set via the penalty parameter. SGD supports the following penalties:
- penalty=”l2”: L2 norm penalty on coef_.
- penalty=”l1”: L1 norm penalty on coef_.
- penalty=”elasticnet”: Convex combination of L2 and L1; rho * L2 + (1 - rho) * L1.
The default setting is penalty=”l2”. The L1 penalty leads to sparse solutions, driving most coefficients to zero. The Elastic Net solves some deficiencies of the L1 penalty in the presence of highly correlated attributes. The parameter rho has to be specified by the user.
SGDClassifier supports multi-class classification by combining multiple binary classifiers in a “one versus all” (OVA) scheme. For each of the K classes, a binary classifier is learned that discriminates between that and all other K-1 classes. At testing time, we compute the confidence score (i.e. the signed distances to the hyperplane) for each classifier and choose the class with the highest confidence. The Figure below illustrates the OVA approach on the iris dataset. The dashed lines represent the three OVA classifiers; the background colors show the decision surface induced by the three classifiers.
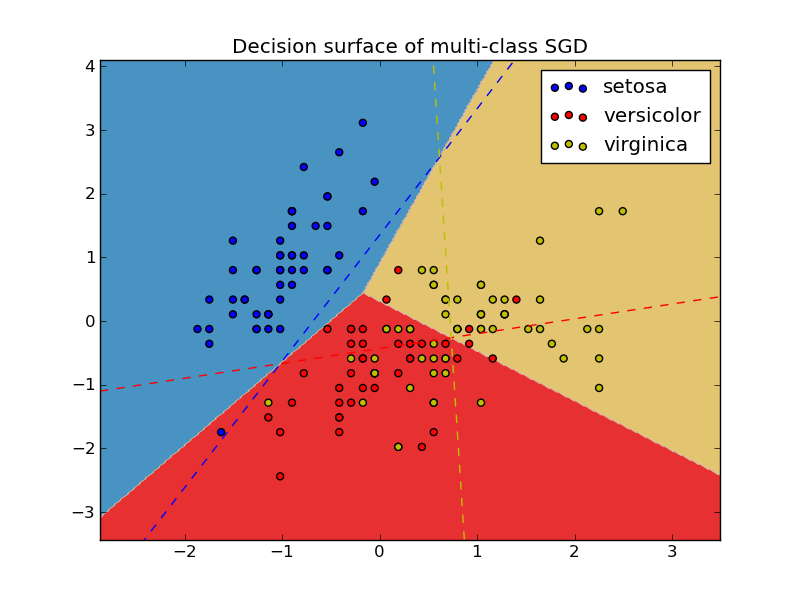
In the case of multi-class classification coef_ is a two-dimensionaly array of shape [n_classes, n_features] and intercept_ is a one dimensional array of shape [n_classes]. The i-th row of coef_ holds the weight vector of the OVA classifier for the i-th class; classes are indexed in ascending order (see member classes).
3.3.2. Regression¶
The class SGDRegressor implements a plain stochastic gradient descent learning routine which supports different loss functions and penalties to fit linear regression models.
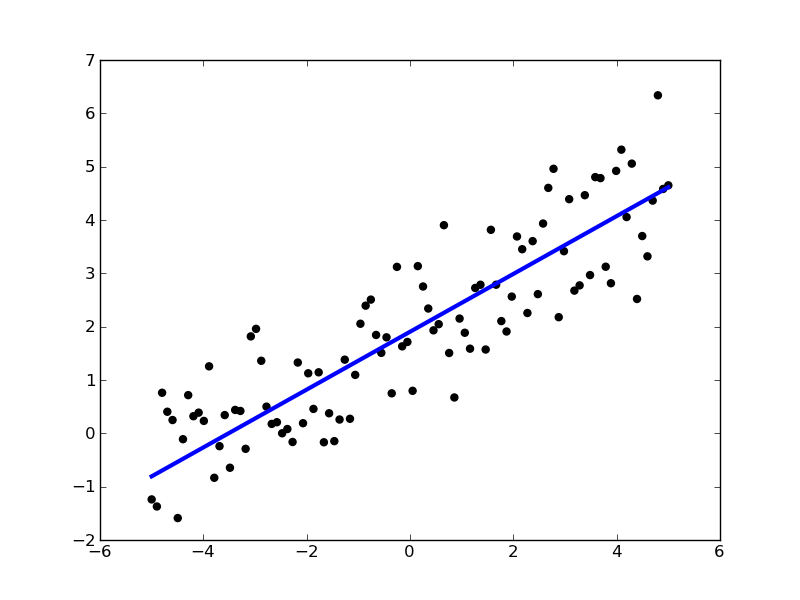
The concrete loss function can be set via the loss parameter. SGDRegressor supports the following loss functions:
- loss=”squared_loss”: Ordinary least squares.
- loss=”huber”: Huber loss for robust regression.
Examples:
3.3.3. Stochastic Gradient Descent for sparse data¶
Note
The sparse implementation produces slightly different results than the dense implementation due to a shrunk learning rate for the intercept.
There is support for sparse data given in any matrix in a format supported by scipy.sparse. Classes have the same name, just prefixed by the sparse namespace, and take the same arguments, with the exception of training and test data, which is expected to be in a matrix format defined in scipy.sparse.
For maximum efficiency, use the CSR matrix format as defined in scipy.sparse.csr_matrix.
Implemented classes are SGDClassifier and SGDRegressor.
3.3.4. Complexity¶
The major advantage of SGD is its efficiency, which is basically
linear in the number of training examples. If X is a matrix of size (n, p)
training has a cost of 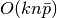 , where k is the number
of iterations (epochs) and
, where k is the number
of iterations (epochs) and 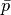 is the average number of
non-zero attributes per sample.
is the average number of
non-zero attributes per sample.
Recent theoretical results, however, show that the runtime to get some desired optimization accuracy does not increase as the training set size increases.
3.3.5. Tips on Practical Use¶
- Stochastic Gradient Descent is sensitive to feature scaling, so it is highly recommended to scale your data. For example, scale each attribute on the input vector X to [0,1] or [-1,+1], or standardize it to have mean 0 and variance 1. Note that the same scaling must be applied to the test vector to obtain meaningful results. See The CookBook for some examples on scaling. If your attributes have an intrinsic scale (e.g. word frequencies or indicator features) scaling is not needed.
- Finding a reasonable regularization term
is best done using grid search for alpha in 10.0**-np.arange(1,7).
- Empirically, we found that SGD converges after observing approx. 10^6 training samples. Thus, a reasonable first guess for the number of iterations is n_iter = np.ceil(10**6 / n), where n is the size of the training set.
References:
- “Efficient BackProp” Y. LeCun, L. Bottou, G. Orr, K. Müller - In Neural Networks: Tricks of the Trade 1998.
3.3.6. Mathematical formulation¶
Given a set of training examples 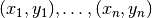 where
where
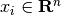 and
and 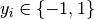 , our goal is to
learn a linear scoring function
, our goal is to
learn a linear scoring function 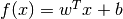 with model parameters
with model parameters
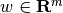 and intercept
and intercept 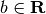 . In order
to make predictions, we simply look at the sign of
. In order
to make predictions, we simply look at the sign of 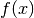 .
A common choice to find the model parameters is by minimizing the regularized
training error given by
.
A common choice to find the model parameters is by minimizing the regularized
training error given by
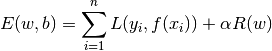
where 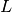 is a loss function that measures model (mis)fit and
is a loss function that measures model (mis)fit and
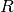 is a regularization term (aka penalty) that penalizes model
complexity;
is a regularization term (aka penalty) that penalizes model
complexity; 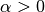 is a non-negative hyperparameter.
is a non-negative hyperparameter.
Different choices for entail different classifiers such as
- Hinge: (soft-margin) Support Vector Machines.
- Log: Logistic Regression.
- Least-Squares: Ridge Regression.
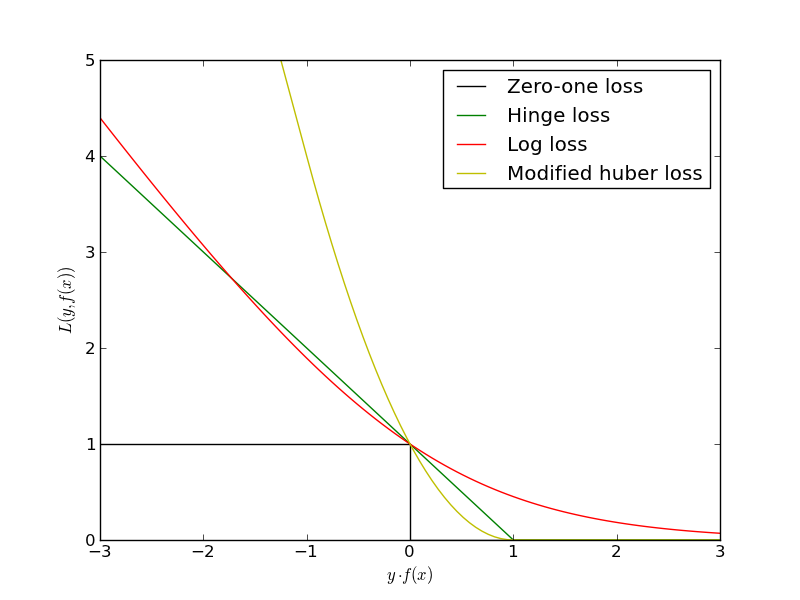
All of the above loss functions can be regarded as an upper bound on the misclassification error (Zero-one loss) as shown in the Figure below.
Popular choices for the regularization term include:
- L2 norm:
,
- L1 norm:
, which leads to sparse solutions.
- Elastic Net:
, a convex combination of L2 and L1.
The Figure below shows the contours of the different regularization terms
in the parameter space when 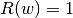 .
.

3.3.6.1. SGD¶
Stochastic gradient descent is an optimization method for unconstrained
optimization problems. In contrast to (batch) gradient descent, SGD
approximates the true gradient of 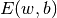 by considering a
single training example at a time.
by considering a
single training example at a time.
The class SGDClassifier implements a first-order SGD learning routine. The algorithm iterates over the training examples and for each example updates the model parameters according to the update rule given by
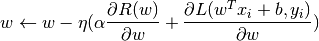
where 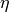 is the learning rate which controls the step-size in
the parameter space. The intercept
is the learning rate which controls the step-size in
the parameter space. The intercept 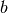 is updated similarly but
without regularization.
is updated similarly but
without regularization.
The model parameters can be accessed through the members coef_ and intercept_:
- Member coef_ holds the weights
- Member intercept_ holds
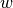
References:
- “Solving large scale linear prediction problems using stochastic gradient descent algorithms” T. Zhang - In Proceedings of ICML ‘04.
- “Regularization and variable selection via the elastic net” H. Zou, T. Hastie - Journal of the Royal Statistical Society Series B, 67 (2), 301-320.
3.3.7. Implementation details¶
The implementation of SGD is influenced by the Stochastic Gradient SVM of Léon Bottou. Similar to SvmSGD, the weight vector is represented as the product of a scalar and a vector which allows an efficient weight update in the case of L2 regularization. In the case of sparse feature vectors, the intercept is updated with a smaller learning rate (multiplied by 0.01) to account for the fact that it is updated more frequently. Training examples are picked up sequentially and the learning rate is lowered after each observed example. We adopted the learning rate schedule from Shalev-Shwartz et al. 2007. For multi-class classification, a “one versus all” approach is used. We use the truncated gradient algorithm proposed by Tsuruoka et al. 2009 for L1 regularization (and the Elastic Net). The code is written in Cython.
References:
- “Stochastic Gradient Descent” L. Bottou - Website, 2010.
- “Pegasos: Primal estimated sub-gradient solver for svm” S. Shalev-Shwartz, Y. Singer, N. Srebro - In Proceedings of ICML ‘07.
- “Stochastic gradient descent training for l1-regularized log-linear models with cumulative penalty” Y. Tsuruoka, J. Tsujii, S. Ananiadou - In Proceedings of the AFNLP/ACL ‘09.