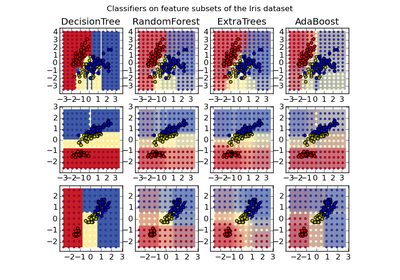
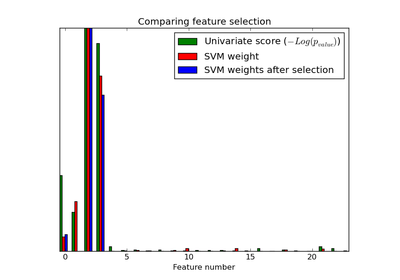
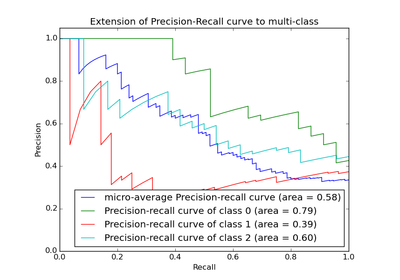
sklearn.datasets.load_iris¶
-
sklearn.datasets.load_iris()[source]¶ Load and return the iris dataset (classification).
The iris dataset is a classic and very easy multi-class classification dataset.
Classes 3 Samples per class 50 Samples total 150 Dimensionality 4 Features real, positive Read more in the User Guide.
Returns: data : Bunch
Dictionary-like object, the interesting attributes are: ‘data’, the data to learn, ‘target’, the classification labels, ‘target_names’, the meaning of the labels, ‘feature_names’, the meaning of the features, and ‘DESCR’, the full description of the dataset.
Examples
Let’s say you are interested in the samples 10, 25, and 50, and want to know their class name.
>>> from sklearn.datasets import load_iris >>> data = load_iris() >>> data.target[[10, 25, 50]] array([0, 0, 1]) >>> list(data.target_names) ['setosa', 'versicolor', 'virginica']